How Does Coupang Handle Massive Traffic
My read notes of Coupang blog series.
Coupang
- A South Korean e-commerce company based in Seoul, South Korea, and incorporated in Delaware, United States.
- Expanded to become the largest online marketplace in South Korea, and referred to as the “Amazon of South Korea”.
- 18M customers.
Our backend strategy to handle massive traffic
If all of Coupang application’s pages each directly called data from the microservices, the microservices would always have to secure high availability, and commonly used business logic code would be duplicated on the frontend without centralized management.
Core serving layer

- Ensure HA (99.99%).
- Serve data with high throughput & low latency.
- Ensure consistency and freshness of data aggregated from various sources in real time.
- Unify business logic code to reduce complexity and code redundancy on the frontend.
Database layer (NoSQL)

- Product domain information is managed by separate microservices in the backend.
- Images and titles are provided by the Catalog Team
- Prices by the Pricing Team
- Stock information by the Fulfillment Team
- Each microservice in the backend sends the updated data to the queue and saves it to the common storage.
- The NoSQL database allows us to leverage eventual consistency and fetch data from all microservices in a single read.
Read-through cache layer

- Serve data with ten times higher throughput and three times less latency compared to the common storage.
Real-time cache layer

- The read-through cache layer provides minutes latency, but some data needs to be updated in a matter of seconds, e.g. stock information.
Scale of two cache layers
- Each layer is composed of 60 ~ 100 nodes.
- Process up to 100M RPS.
- 95% of the incoming traffic is processed by the cache layers instead of the common storage layer.
High availability strategies

- CSP a.k.a. critical serving path
- N-CSP a.k.a. non critical serving path
Core serving layer template

Lessons learned from handling massive traffic with cache
Lesson 1: Managing partial cache node failure

- In addition to monitoring topology refresh, we decided to monitor TCP connection speeds.
- Connections without responses for one second were marked problematic and the connections to that node are automatically closed.

Lesson 2: Quickly recovering failed nodes
- When a node fails, it must go through a full sync process for recovery.
- The incoming traffic to the cache layer was higher than the amount of traffic the buffer could handle.
- They experienced frequent failures during the full sync and node recovery process.
Finding the root cause

Blocking traffic to defective replicas
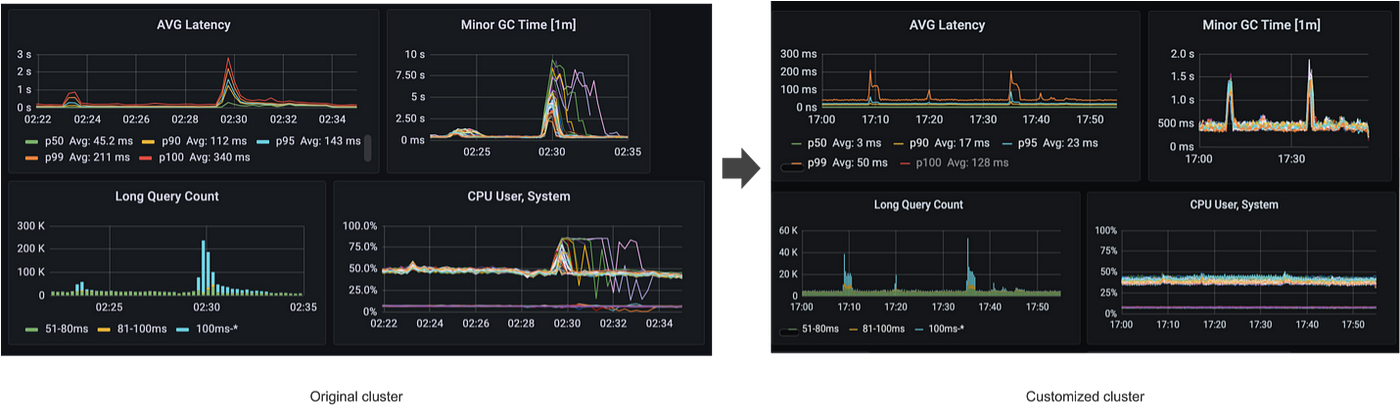
Lesson 3: Balancing traffic between nodes
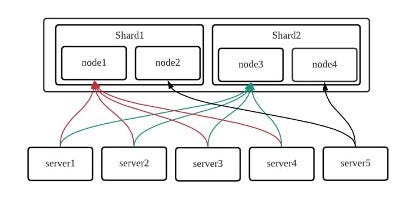
- Route randomly instead of route according to connection time.
Lesson 4: Handling traffic spikes using local cache
- Although growing user traffic is good news for business, it may not always be welcomed by server engineers.
- During COVID-19, we frequently saw unexpected spikes in traffic.
- They had no choice but to secure three times the recommended server capacity for application stability.
Traffic analysis
- Store the incoming requests to the message queue and used MapReduce to analyze user and product information of the requests on a minute basis.
- The analysis revealed that most traffic spikes during COVID-19 were related to face mask restocks.
Local cache

- Challenges
- Cache invalidation
- GC counts and times
- Cache data that could be updated with eventual consistency, not strong consistency in only one minute.
- Save data in a byte array format instead of the DTO(Data Transfer Object) format
Non-blocking I/O
- With this change, we reduced CPU usage by more than 50% and used NIO threads to minimize CPU overhead.